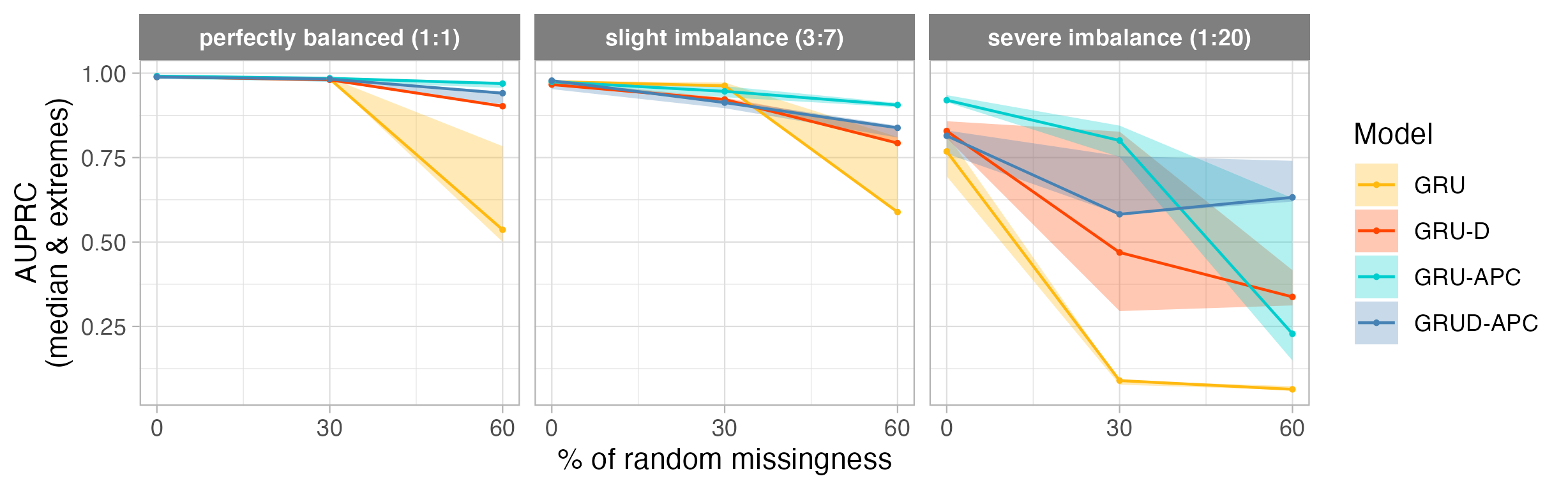
Comparison of time series models as a function of missing data (x axis), and class imbalance (three plots). We see that baseline models (GRU & GRU-D with class-reweighting) perform significantly worse than models pre-trained with APC (auto-regressive predictive coding). These results suggest APC as an effective self-supervised learning method for handling missing data and class imbalance simultaneously.
As easy as APC:
overcoming missing data and class imbalance in time series with self-supervised learning
Abstract.
High levels of missing data and strong class imbalance are ubiquitous challenges that are often presented simultaneously in real-world time series data. Existing methods approach these problems separately, frequently making significant assumptions about the underlying data generation process in order to lessen the impact of missing information. In this work, we instead demonstrate how a general self-supervised training method, namely Autoregressive Predictive Coding (APC), can be leveraged to overcome both missing data and class imbalance simultaneously without strong assumptions. Specifically, on a synthetic dataset, we show that standard baselines are substantially improved upon through the use of APC, yielding the greatest gains in the combined setting of high missingness and severe class imbalance. We further apply APC on two real-world medical time-series datasets, and show that APC improves the classification performance in all settings, ultimately achieving state-of-the-art AUPRC results on the Physionet benchmark.
Authors
Fiorella Wever, T. Anderson Keller, Laura Symul, Victor Garcia Satorras
Full Paper
Accepted at:
Self-Supervised Learning workshop at NeurIPS 2021 (Poster)
Women in Machine Learning workshop at NeurIPS 2021
ArXiv Paper: https://arxiv.org/abs/2106.15577

{kind=link}
Autoregressive Predictive Coding (APC):
An input sequence x is given to the model, which uses an RNN encoder to encode the value at each time step to a hidden state. Finally, a weight matrix W transforms the hidden states to same dimensionality as the input sequence x. A time shifting factor of n ≥ 1 tells the encoder to predict n steps in the future ahead of the current one. The output sequence y is then compared to the input sequence x shifted n steps ahead in order to compute the loss.